Cufflinks basic
cufflinks는 pandas.DataFrame형태의 데이터를 plotly를 이용해 쉽게 시각화할 수 있도록 도와주는 라이브러리이다.
데이터프레임을 가지고 간단하게 인터렉티브한 그래프를 만들 수 있다는 장점이 있지만, svg만 사용하다보니 만개를 넘어가는 산점도 등 복잡한 형태의 그래프를 그릴 때에는 좋은 결과물을 얻기 힘들다. (plotly에서는 그냥 webgl을 쓰면 되는데…. cufflinks에 없는건지 내가 못찾는건지 ㅠㅠ)
최종적인 시각화 결과물을 내는 데에는 부족하지만 (그 퀄리티를 내려면 plotly를 쓰셔야 합니다…) 분석을 위한 간단한 그래프를 빠르게 찍어내는데는 상당히 유용하게 사용할 수 있다.
import pandas as pd
import cufflinks as cf
cf.go_offline()
사용한 라이브러리 버전은 다음과 같다
# cufflinks
cf.__version__
'0.8.2'
# pandas
pd.__version__
'0.18.1'
데이터 불러오기
연습/테스트용으로 많이 사용되는 데이터를 불러와서 그래프를 그려보자. 라이브러리에서 데이터를 제공하는 경우도 있지만 적당한 데이터를 찾지 못했다면 아래 url 링크를 통해 데이터를 불러와서 진행하면 된다.
pandas.read_csv() 를 통해 csv 데이터를 데이터 프레임으로 변환시킨다
diamonds = pd.read_csv('https://raw.githubusercontent.com/hadley/ggplot2/master/data-raw/diamonds.csv')
economics = pd.read_csv('https://raw.githubusercontent.com/hadley/ggplot2/master/data-raw/economics.csv')
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
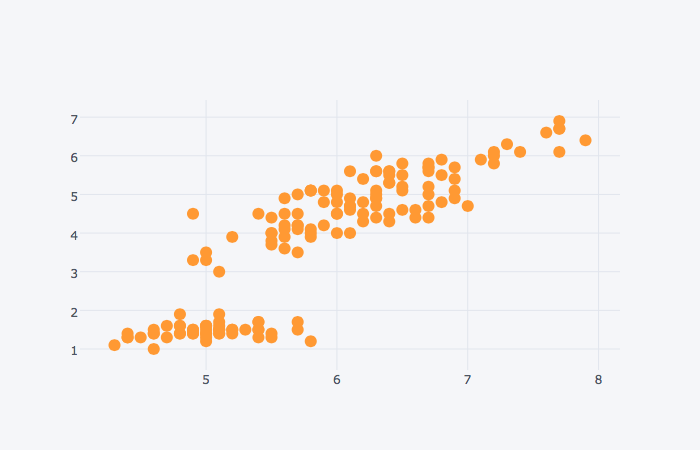
산점도 (Scatter Plot)
불러온 데이터 중에서 iris 데이터를 가지고 간단한 산점도를 그려보자. 데이터는 다음과 같이 구성되어 있다.
iris.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
데이터프레임.iplot() 을 통해 jupyter notebook에 그래프를 바로 그릴 수 있다. 독립적인 html 파일로 그래프를 출력한다면 데이터프레임.plot()을 사용하면 된다.
(iris
.iplot(kind='scatter', mode='markers', # markers 옵션이 빠지면 '선'의 형태로 표시됨
x='sepal_length', y='petal_length') # x, y를 명시하지 않으면 index가 x축으로 지정됨
)
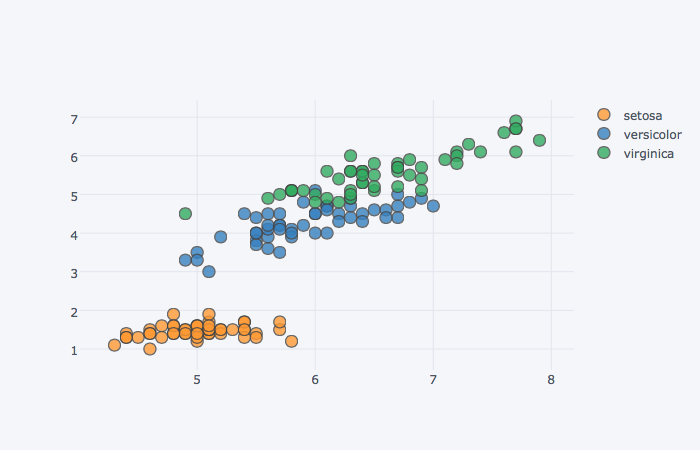
그룹별로 그리기
categories 항목에 그룹으로 지정할 열 이름을 넣으면 그룹별 산점도를 그릴 수 있다
(iris
.iplot(kind='scatter', mode='markers',
x='sepal_length', y='petal_length', categories='species') # categories 항목에 해당 열 이름을 추가
)
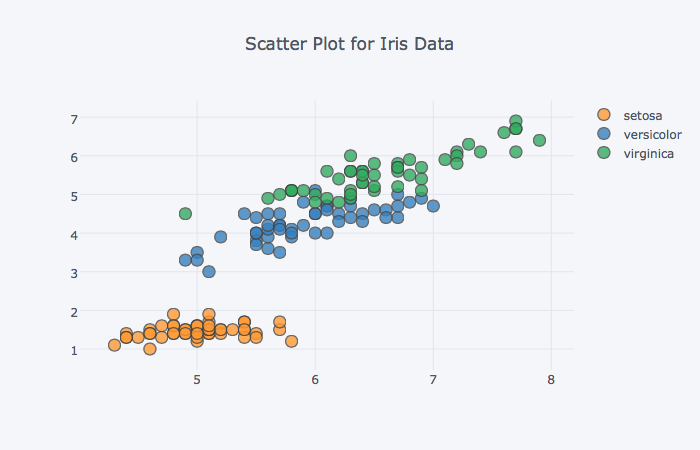
제목 추가하기
기본 plotly에서는 레이아웃을 직접 지정해야했지만, cufflinks에서는 title 옵션을 통해 제목을 추가할 수 있다
(iris
.iplot(kind='scatter', mode='markers',
x='sepal_length', y='petal_length', categories='species',
title='Scatter Plot for Iris Data') # title에 제목을 추가한다
)
Subplot 구성하기
subplots=True 항목을 추가하면 각 항목의 그래프를 나누어서 그릴 수 있다
(iris
.iplot(kind='scatter', mode='markers',
x='sepal_length', y='petal_length', categories='species',
subplots=True, # subplots=True 를 추가
title='Scatter Plot for Iris Data')
)
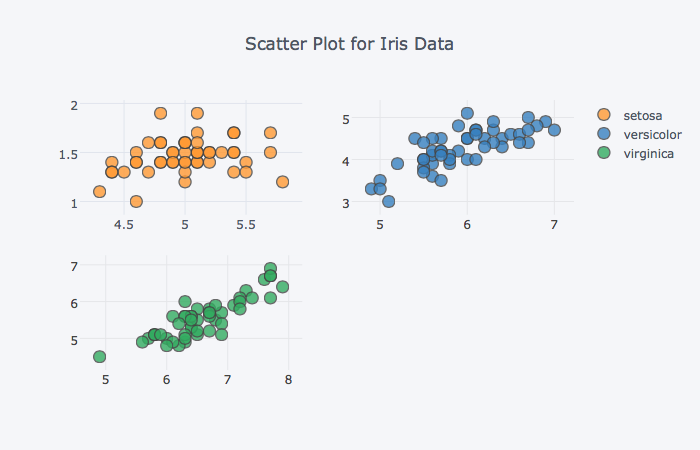
어차피 각 항목별로 그래프가 나누어져있으니 범례를 지우고 각 subplot에 소제목을 추가해보자
subplot_titles=True로 설정하면 각 subplot에 소제목이 추가된다legend=False를 설정하면 범례가 보이지 않는다
(iris
.iplot(kind='scatter', mode='markers',
x='sepal_length', y='petal_length', categories='species',
subplots=True, subplot_titles=True, legend=False,
title='Scatter Plot for Iris Data')
)
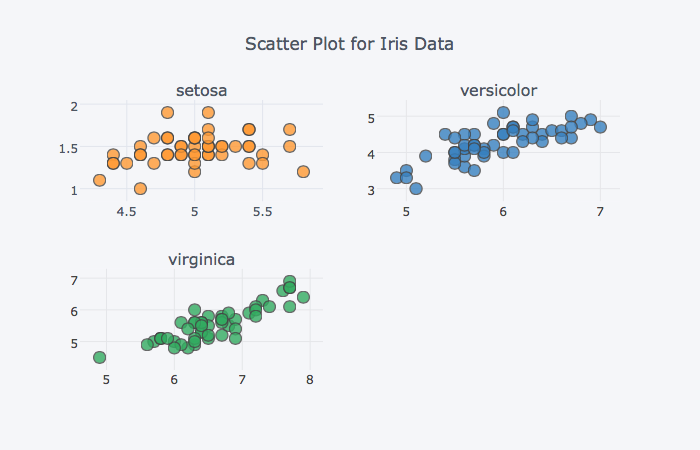
subplot의 배치방식을 바꾸려면 shape 옵션을 변경해주면 된다. shape=(행, 열)의 형태로 정수값을 입력한다.
옆으로 나란히 세 개의 그래프를 배치해보자
(iris
.iplot(kind='scatter', mode='markers',
x='sepal_length', y='petal_length', categories='species',
subplots=True, subplot_titles=True, legend=False,
shape=(1,3), # shape=(원하는 행 수, 원하는 열 수)
title='Scatter Plot for Iris Data')
)

막대그래프
이번에는 diamonds 데이터를 가지고 막대그래프를 그려보려고 한다. 데이터는 다음과 같이 구성되어 있다.
diamonds.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
막대그래프를 사용하려면 kind='bar'로 지정하면 된다
- ‘bar’ 는 세로 방향의 막대그래프
- ‘barh’는 가로 방향의 막대그래프를 그릴 수 있다
cut 변수를 기준으로 하여 그룹별로 항목의 갯수를 세어보고 막대그래프에 나타내어 보자.
dia_cut = (diamonds
.groupby('cut')
.size()
.sort_values()
)
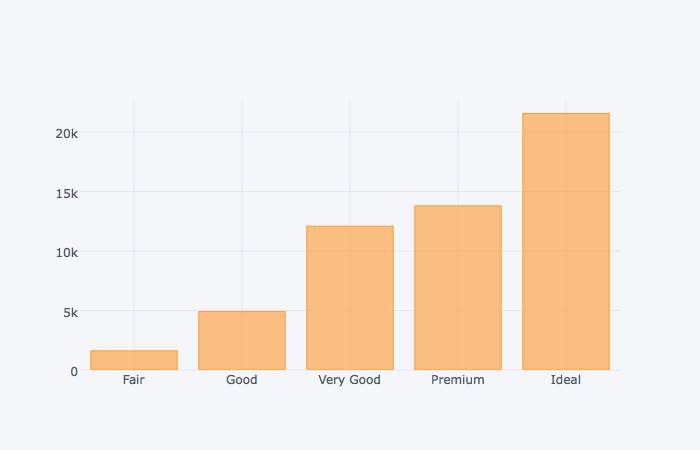
dia_cut
cut
Fair 1610
Good 4906
Very Good 12082
Premium 13791
Ideal 21551
dtype: int64
dia_cut.iplot(kind='bar')
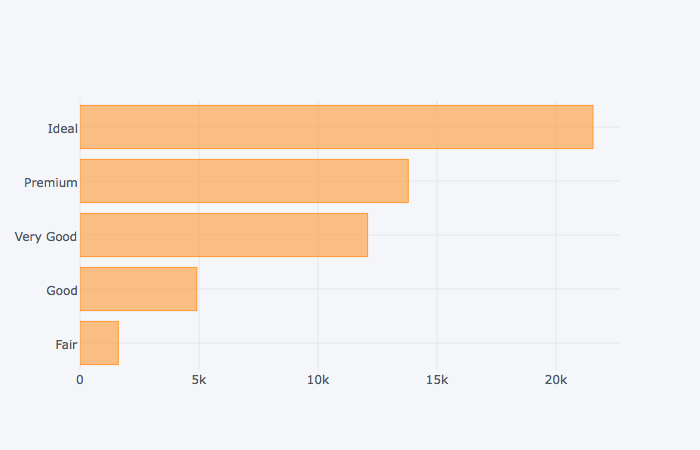
dia_cut.iplot(kind='barh')
적당한 제목을 추가해보자!!
위에서 했던 것과 마찬가지로 title 값을 채워주면 된다.
dia_cut.iplot(kind='bar', title='다이아몬드 데이터')
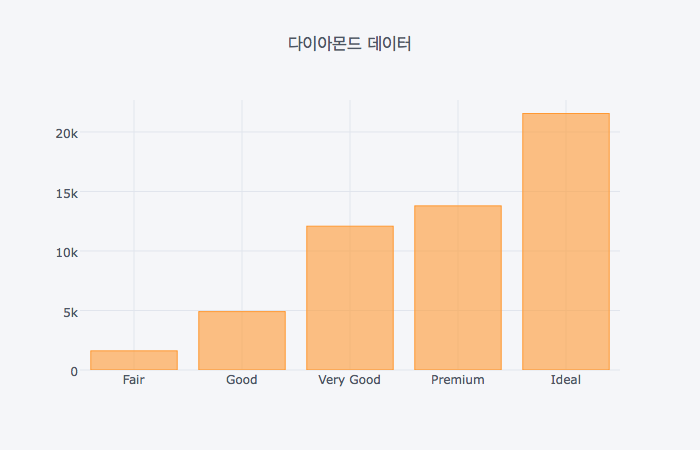
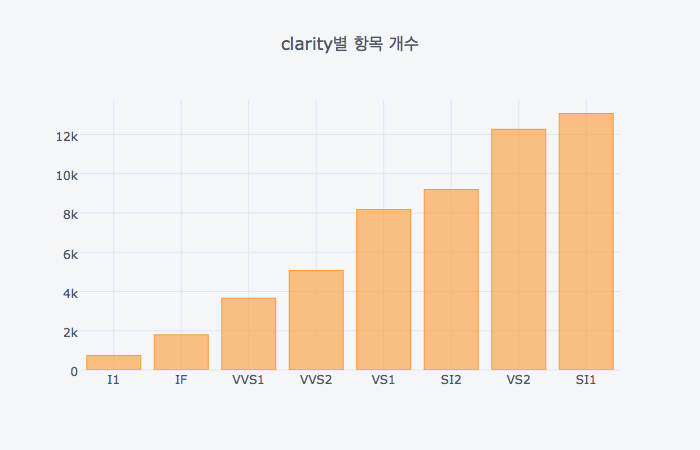
clarity별로 항목의 개수를 집계해서 막대그래프를 만들어보자
cut이 아니라 clarity를 기준으로 집계한다면 다음과 같은 결과물이 나온다.
(diamonds
.groupby('clarity')
.size()
.sort_values()
.iplot(kind='bar', title='clarity별 항목 개수')
)
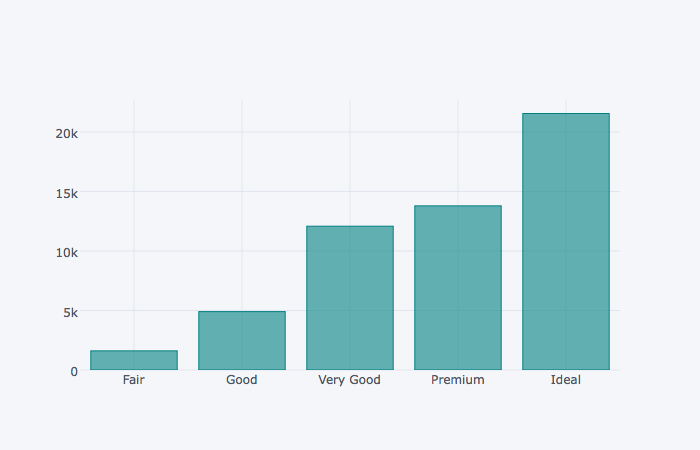
막대 색상변경하기
colors옵션을 변경하면 막대의 색상을 지정할 수 있다
색상은 다양한 방식으로 지정할 수 있다
- 지정된 색상이름
- #로 시작하는 색상 코드
- 문자열로 지정된 rgb 값 ‘rgb(10,10,10)’
dia_cut.iplot(kind='bar', colors='teal')
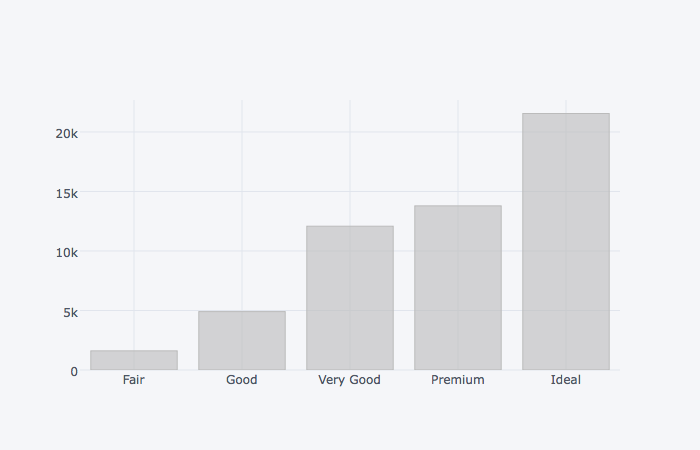
dia_cut.iplot(kind='bar', colors='#bbbbbb')
dia_cut.iplot(kind='bar', colors='rgb(100,30,30)')
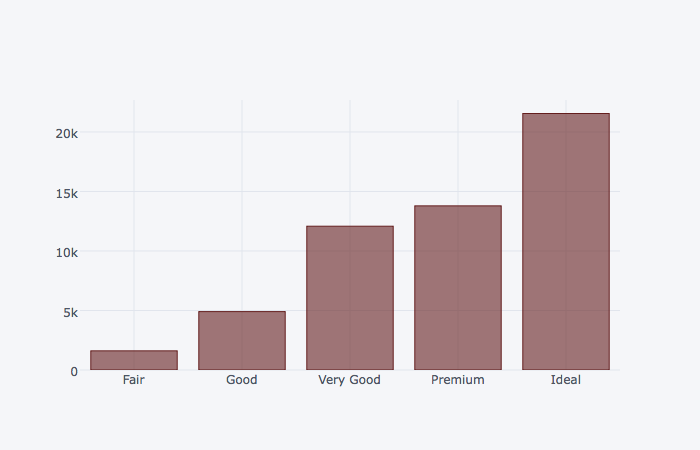
그룹별 막대그래프
- x축에 들어가려는 값은
index에 놓고 - 그룹으로 나누려는 값은
column으로 구분한다
데이터를 정리한 후에, unstack 메서드를 이용해서 그래프를 그릴 수 있는 형태로 변경한다
dia_cutcolor = (diamonds
.groupby(['cut', 'color'])
.size()
)
dia_cutcolor
cut color
Fair D 163
E 224
F 312
G 314
H 303
I 175
J 119
Good D 662
E 933
F 909
G 871
H 702
I 522
J 307
Ideal D 2834
E 3903
F 3826
G 4884
H 3115
I 2093
J 896
Premium D 1603
E 2337
F 2331
G 2924
H 2360
I 1428
J 808
Very Good D 1513
E 2400
F 2164
G 2299
H 1824
I 1204
J 678
dtype: int64
dia_cutcolor.unstack('color')
| color | D | E | F | G | H | I | J |
|---|---|---|---|---|---|---|---|
| cut | |||||||
| Fair | 163 | 224 | 312 | 314 | 303 | 175 | 119 |
| Good | 662 | 933 | 909 | 871 | 702 | 522 | 307 |
| Ideal | 2834 | 3903 | 3826 | 4884 | 3115 | 2093 | 896 |
| Premium | 1603 | 2337 | 2331 | 2924 | 2360 | 1428 | 808 |
| Very Good | 1513 | 2400 | 2164 | 2299 | 1824 | 1204 | 678 |
color를 기준으로 unstack한 상태에서 iplot을 통해 그래프를 그린다.
(dia_cutcolor
.unstack('color')
.iplot(kind='bar')
)
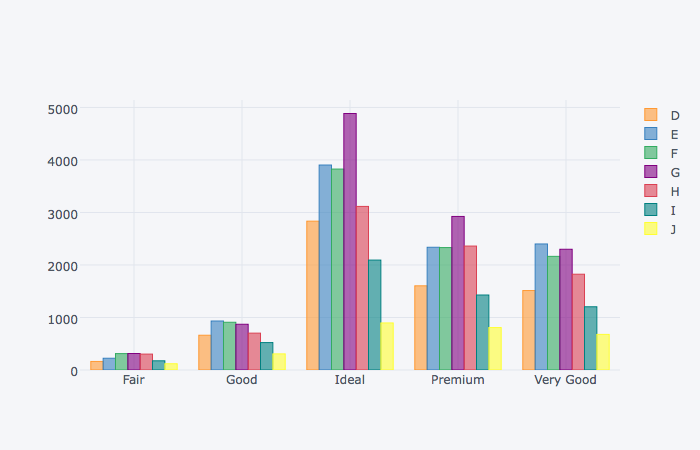
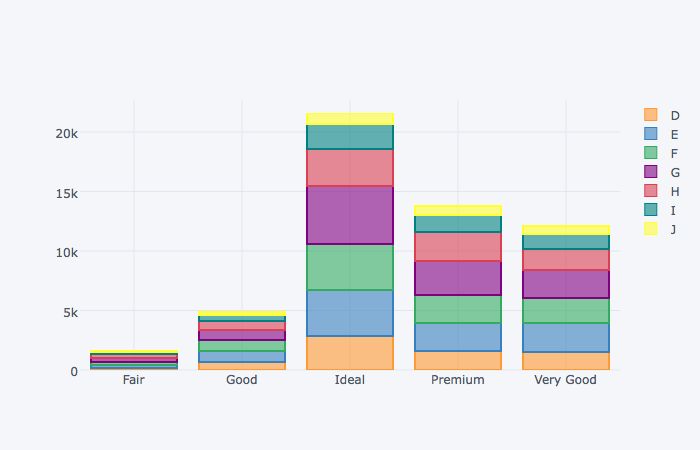
누적막대그래프
plotly와 마찬가지로, barmode='stack'을 추가하면 된다
(dia_cutcolor
.unstack('color')
.iplot(kind='bar', barmode='stack')
)
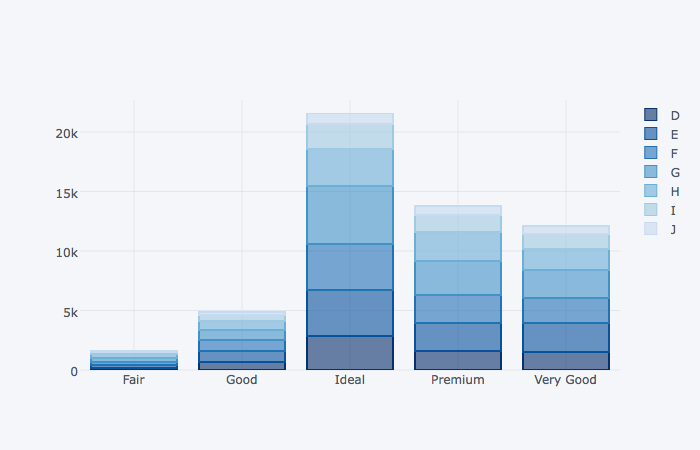
색상 팔레트 적용하기
기본 색상팔레트 이외에 정의되어있는 팔레트를 적용할 수 있다
cf.colors.scales()함수를 통해 적용할 수 있는 팔레트의 목록과 이름을 확인할 수 있으며- 팔레트 이름 앞에
-를 붙이면 색상의 순서를 반대로 적용할 수 있다
cufflinks의 색상관련 내용은 다음 링크에 자세히 설명되어 있다.
http://nbviewer.jupyter.org/gist/santosjorge/00ca17b121fa2463e18b
(dia_cutcolor
.unstack('color')
.iplot(kind='bar', barmode='stack', colorscale='blues')
)

(dia_cutcolor
.unstack('color')
.iplot(kind='bar', barmode='stack', colorscale='-blues') # 색상의 순서를 반대로 지정하려면 색상명 앞에 `-`를 붙인다
)
사용할 수 있는 색상조합은 아래와 같이 확인할 수 있다. 데이터의 특성에 맞는 조합을 사용해야 한다.
cf.colors.scales()

선그래프
kind='scatter' 일 경우 기본값으로 선 그래프를 그린다.
economics.iplot(kind='scatter', x='date', y='unemploy')

x에 date만 적용하고 나머지 변수들로 subplot을 그려보자
economics.iplot(kind='scatter', x='date', subplots=True)

그래프 전체 크기 조절하기
그래프의 전체 크기를 조절하려면 dimensions 옵션에 원하는 사이즈를 튜플 형태로 넘긴다
다섯 개의 그래프를 세로로 나란히 배치하고 그래프 전체의 사이즈를 조절해보자
economics.iplot(kind='scatter', x='date',
subplots=True, subplot_titles=True, legend=False,
shape=(5,1), # 5행, 1열
dimensions=(800,1000)) # 가로 800, 세로 1000

Shared Axes
shared_yaxes(또는 shared_xaxes)를 적용하면 subplot별로 같은 축을 사용하도록 강제할 수 있다
다만 subplot의 위치에도 영향을 받기 때문에 모든 그래프에 동일한 y축 범위를 적용하려면 아래와 같이 row수가 1로 고정되어야 한다
economics.iplot(kind='scatter', x='date',
subplots=True, subplot_titles=True, legend=False,
shared_yaxes=True,
shape=(1,5), dimensions=(1000,400))

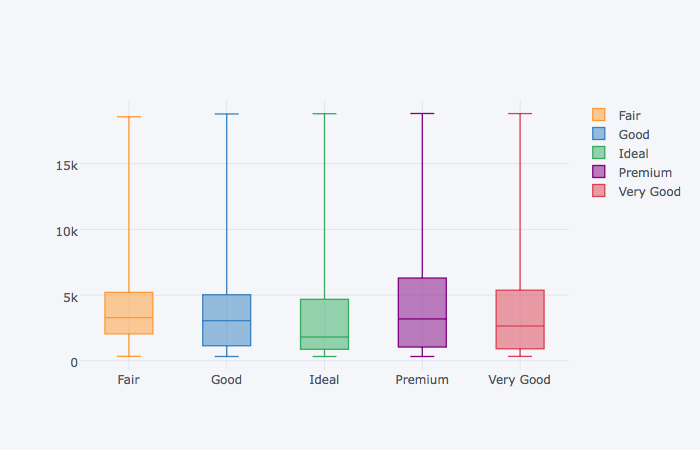
Box Plot
그룹별 Box Plot은 약간의 편법(?)을 통해서 만들 수 있다.
- 그룹으로 지정하려고 하는 열과 y축 값을 나타내려는 열만 남긴다
- 그룹으로 지정하려고 하는 열을 인덱스로 지정한다(
append=True옵션을 통해 row number를 남기자) unstack메서드를 사용해서 각 그룹을 열로 구성한다- 이로 인해 엄청난 양의 NaN값이 생기지만 무시하고 그래프를 그린다!
(diamonds
.loc[:, ['cut', 'price']]
.set_index('cut', append=True)
.unstack('cut')['price']
.iplot(kind='box')
)