

데이터를 다루는 사람들은 다양한 형태로 그래픽을 활용합니다. 실시간으로 변하는 그래프를 보며 대응하기도 하고, 공들여 분석한 내용을 클라이언트에게 잘 설명하기 위해 슬라이드에 넣을 그래프를 작성하기도 합니다. 대중을 대상으로 하는 인포그래픽을 만들거나 논문에 들어갈 전문적인 도표를 만들 수도 있습니다. 목적과 대상은 모두 다릅니다. 하지만 데이터를 시각적으로 잘 표현해야 한다는 것은 동일합니다.
데이터를 시각적으로 잘 나타낼 수 있으려면 어떻게 해야 할까요? 처음에는 우리가 어떤 차트를 쓸 수 있는지 조차도 잘 모르는 상태에서 시작합니다. 엑셀이나 다른 도구들이 제공하는 간단한 차트 도구를 통해 데이터를 표현하는 방법을 익히게 될 것입니다. 하지만 어느 순간부터는, 복잡한 시각화를 위해서는 데이터를 그래픽으로 표현하는 과정에 대한 체계적인 고민이 필요해집니다. 이러한 과정은 우리가 언어를 통해 의사소통하는 것과 비슷하지 않을까요? 언어를 처음 배울 때 몇 가지 단어를 가지고 단순한 소통을 시작합니다. 그러다가 단어를 조합하고, 더 복잡한 문법을 구사할 수 있게 되면 언어를 통해 엄청나게 다양한 표현을 할 수 있게 됩니다. 다시 데이터로 돌아오면, 데이터 시각화를 위한 문법을 체계적으로 구성할 수 있다면 우리는 차트라는 파편화된 단어를 넘어서 무한에 가까운 표현력을 얻을 수 있을 겁니다.
시각화 문법은 그래프를 구성하는 요소로 어떤 것들이 필요한지 청사진을 보여주는 역할을 합니다. 이러한 문법 체계는 우리의 머리 속에 있는 것들을 실제로 구현하는 과정을 단축시키는데 도움을 줍니다. 또한 복잡한 형태의 시각화도 체계적으로 구성할 수 있습니다. 개발자의 입장에서는 새로운 기능을 일관성 있게 추가할 수 있으며, 사용자의 입장에서는 일관적인 문법 체계를 바탕으로 쉽게 그래프를 작성하거나 수정할 수 있으니 편리해집니다.
여기서는 Leland Wilkinson 의 Grammar of Graphics 와 Hadley Wicham 의 변형된 형태에 대해서 간단히 살펴보겠습니다.
Leland Wilkinson : Grammar of graphics
데이터로 그래프를 만들기 위해 필요한 작업들
Wilkinson의 Grammar of graphics 에서는 데이터를 가지고 그래픽을 만들어내는데 다음과 같은 7가지 단계가 필요하다고 말합니다.
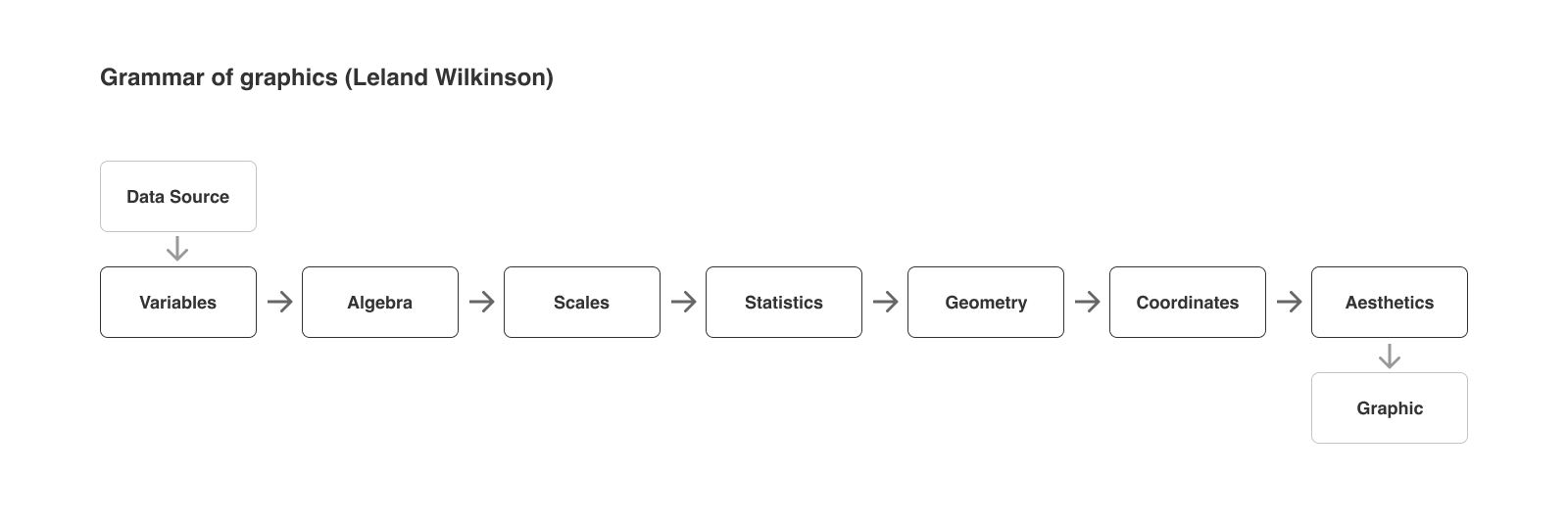
- (1) Create Variables
- 데이터 소스에서 원하는 변수를 추출하고, 필요한 경우 값을 변환합니다.
- SQL의 SELECT 문에 해당하는 작업입니다.
- (2) Apply Algebra
- 여러 변수에 연산을 적용하여 원하는 형태의 데이터를 구성합니다.
- SQL의 JOIN, UNION ALL 등의 작업을 의미합니다.
- (3) Apply Scales
- 변수들 사이의 관계나, 데이터가 의미하는 바가 잘 나타나도록 값을 변환합니다.
- 카테고리 변수를 잘 구분할 수 있도록 색상이나 순서로 변환합니다.
- 숫자 변수의 특성을 잘 나타낼 수 있도록 변환합니다. (Linear, Log, Pow 등)
- 시간에 따른 변화를 나타낼 수 있도록 변환합니다. (연도, 월, 일, 시간 등)
- 변수들 사이의 관계나, 데이터가 의미하는 바가 잘 나타나도록 값을 변환합니다.
- (4) Compute Statistics
- 그래프에 표현될 기하학적인 객체에 반영하기 위한 목적으로 데이터를 변환합니다.
- 이 작업을 데이터 정제 작업과 독립적으로 둘 수 있으면, 동일한 데이터에서 평균과 분산을 각각 계산하여 시각화 하는 것도 가능해집니다.
- (5) Construct Geometry
- 점, 선, 면 등 기하학적인 요소를 통해 데이터를 표현합니다.
- 같은 위치에서 여러 그래픽 요소가 겹쳐있는 경우 별도의 작업을 추가하여 해결합니다.
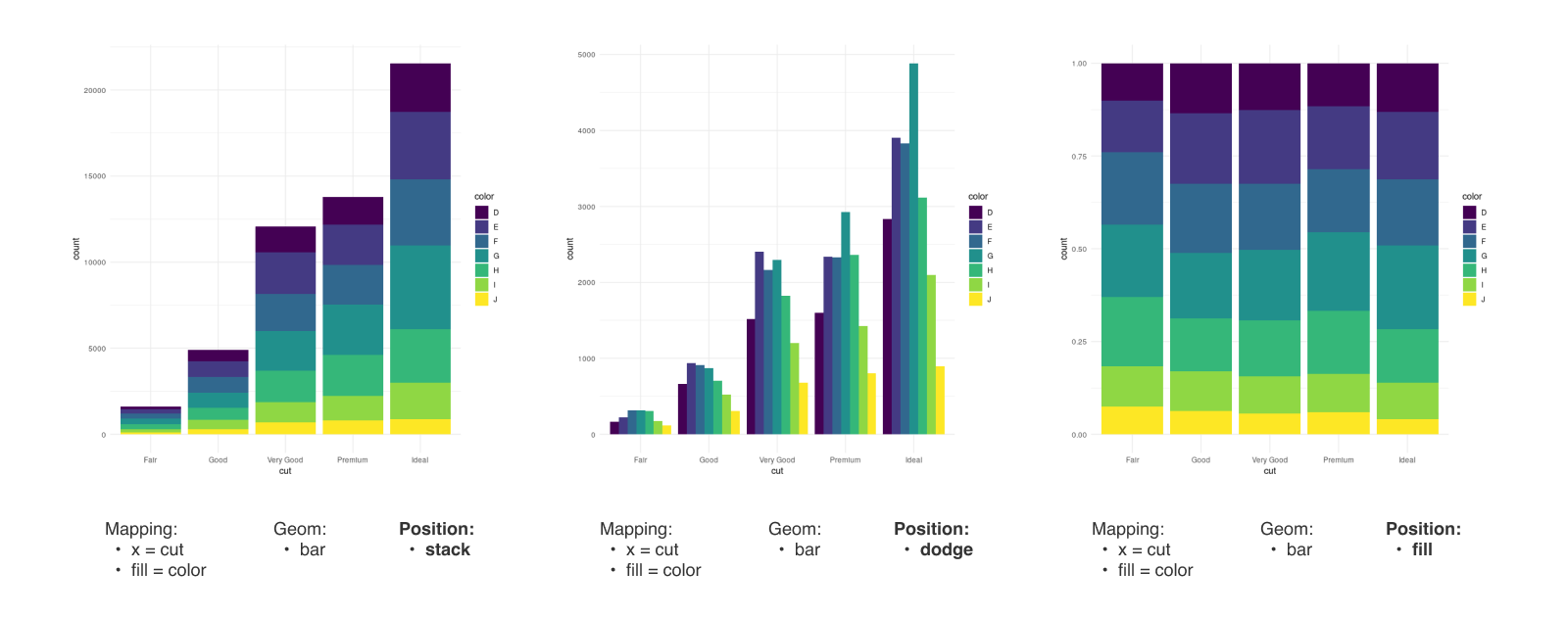
- 막대가 겹치는 경우에는 누적 막대로 쌓거나(stack) 막대를 옆으로 나란히 배치(dodge)할 수 있습니다.
- 점이 겹치는 경우에는 좌우로 흩뿌려서(jitter) 겹치는 점을 표현할 수 있습니다.
- 위와 같은 작업을 Collision Modifier 라고 합니다.
- (6) Apply Coordinates
- 좌표계를 통해 특정한 점을 그래프에 어떻게 표시할지 결정합니다.
- 원하는 내용을 잘 표현하기 위한 목적으로 좌표계를 회전하거나, 왜곡할 수 있습니다.
- (7) Compute Aesthetics
- Geometry 객체에 크기, 두께, 색상, 질감 등 추가적인 속성을 부여합니다.
- Aesthetics Attributes 는 그래프에서 우리가 시각적으로 구분할 수 있는 미적인 요소들을 의미합니다.
결과적으로 우리는 6가지 항목을 통해 그래픽 스펙을 설명할 수 있습니다.
- DATA → 데이터셋에서 추출한 변수들의 집합을 말합니다.
- TRANS → 변수 변환을 의미합니다. (sort, rank, residual 등)
- SCALE → 스케일 변환을 의미합니다. (log 등)
- COORD → 좌표계를 의미합니다. (cartesian, polar 등)
- ELEMENT → 그래픽으로 표현할 대상(점, 막대 등)과 표현에 필요한 시각적 요소(크기, 색상 등)를 말합니다.
- GUIDE → 축, 범례 등 데이터를 이해하는데 도움을 주는 가이드 요소를 말합니다.
CASE : 막대그래프
아래와 같은 데이터셋을 가지고 문법에 맞게 막대 그래프를 만들어봅시다. 세부적인 과정을 설명할 수 있도록 간단한 의사코드(pseudocode)를 표시하고, 데이터셋이 변화하는 과정을 함께 표시하겠습니다. 아래 과정에서 작성하는 의사코드는 Wilkinson의 책에서 사용하는 표기 방법을 일부 수정하여 사용했습니다.
cut color
1 Ideal E
2 Premium E
3 Good E
4 Premium I
5 Good J
6 Very Good J
7 Very Good I
8 Very Good H
9 Fair E
10 Very Good H
# … with 53,930 more rows
(1) Create Variables
데이터에서 필요한 변수를 추출합니다.
Cut = loadFromDataSource("Diamonds", "cut")
Color = loadFromDataSource("Diamonds", "color")
(2) Apply Algebra
다른 소스의 데이터를 JOIN 하거나 UNION 할 경우 이 단계에서 처리합니다.
(3) Apply Scales
카테고리 변수에 Scale을 적용합니다. 여기서는 각 항목의 인덱스에 맞는 정수값을 적용합니다.
category(Cut, values("Fair", "Good", "Very Good", "Premium", "Ideal"))
category(Color, values("D", "E", "F", "G", "H", "I", "J"))
------
cut color cut_index color_index
1 Ideal E 5 2
2 Premium E 4 2
3 Good E 2 2
4 Premium I 4 6
5 Good J 2 7
6 Very Good J 3 7
7 Very Good I 3 6
8 Very Good H 3 5
9 Fair E 1 2
10 Very Good H 3 5
# … with 53,930 more rows
(4) Compute Statistics
이 과정에서는 Variable set 하나가 그래픽 요소 하나에 매칭될 수 있도록 데이터를 변환한다. 데이터의 1행이 하나의 그래픽 요소로 표현되도록 한다고 보면 됩니다. 막대 그래프를 그리기 위해서는 cut, color 항목의 조합에 따라 하나의 요약된 값으로 정리해야 합니다.
아래 의사코드에서는 summary.count() 라는 작업을 정의해서 두 카테고리 변수에 해당하는 데이터 수를 계산합니다.
summary.count()
------
cut color cut_index color_index count
1 Fair D 1 1 163
2 Fair E 1 2 224
3 Fair F 1 3 312
4 Fair G 1 4 314
5 Fair H 1 5 303
6 Fair I 1 6 175
7 Fair J 1 7 119
8 Good D 2 1 662
9 Good E 2 2 933
10 Good F 2 3 909
# … with 25 more rows
(5) Construct Geometry
다양한 그래픽 표현 방식 중에서 막대 형태를 사용하겠습니다. 해당 Geometry는 0이 아닌 길이를 가지는 막대를 사용해 데이터를 표현합니다. 카테고리 변수가 2개나 있기 때문에, 막대 중에서도 누적(stack) 막대를 사용합니다. 이 경우 각 데이터의 이전 막대에 이어 붙이는 형태로 표현됩니다.
interval.stack(
position(summary.count(cut*color))
)
------
cut color color_index start_count end_count
1 Fair D 1 0 163
2 Fair E 2 163 387
3 Fair F 3 387 699
4 Fair G 4 699 1013
5 Fair H 5 1013 1316
6 Fair I 6 1316 1491
7 Fair J 7 1491 1610
8 Good D 1 0 662
9 Good E 2 662 1595
10 Good F 3 1595 2504
# … with 25 more rows
(6) Apply Coordinates
여기서는 가장 기본적인 Rectangular(Cartesian) Coordinates를 사용합니다. 만약 이 부분에서 극좌표계(Polar Coordinates)를 사용할 경우, 막대에서 파이 그래프로 변하게 됩니다.
rect(dim(1, 2))
(7) Compute Aesthetics
막대 내에서 color 변수를 구분할 수 있도록 color_index 값에 맞는 색상을 부여합니다. 외곽선, 투명도 등 막대에 추가적인 시각적 속성을 적용하려면 이 단계에서 반영합니다.
cut color color_index start_count end_count bar_color
1 Fair D 1 0 163 #66C2A5
2 Fair E 2 163 387 #FC8D62
3 Fair F 3 387 699 #8DA0CB
4 Fair G 4 699 1013 #E78AC3
5 Fair H 5 1013 1316 #A6D854
6 Fair I 6 1316 1491 #FFD92F
7 Fair J 7 1491 1610 #E5C494
8 Good D 1 0 662 #66C2A5
9 Good E 2 662 1595 #FC8D62
10 Good F 3 1595 2504 #8DA0CB
# … with 25 more rows
결과적으로 우리가 완성한 막대 그래프는 다음과 같은 스펙으로 표현할 수 있습니다.
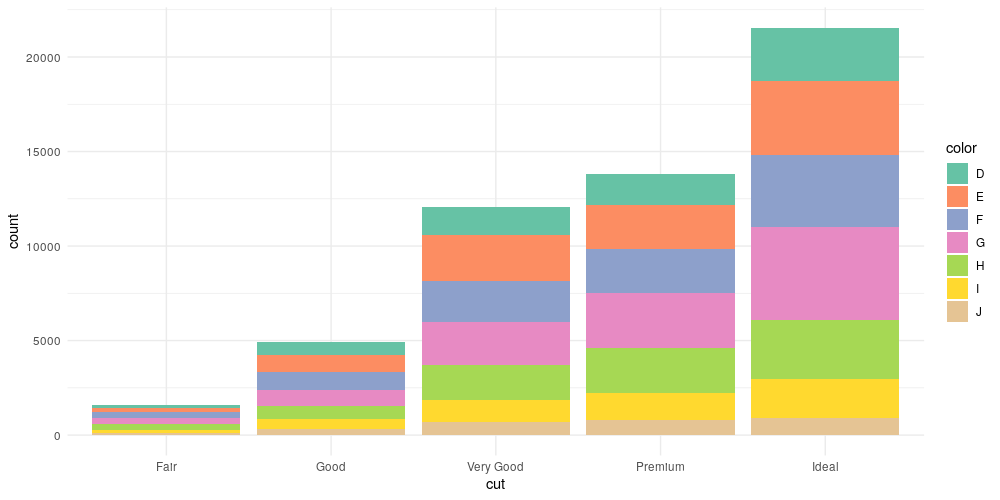
DATA:
- Cut: loadFromDataSource("Diamonds", "cut")
- Color: loadFromDataSource("Diamonds", "color")
SCALE:
- category(Cut, values("Fair", "Good", "Very Good", "Premium", "Ideal"))
- category(Color, values("D", "E", "F", "G", "H", "I", "J"))
COORD:
- rect(dim(1, 2))
ELEMENT:
- interval.stack
- position(summary.count(cut*color))
- label(cut)
- color(color)
GUIDE:
- legend.color(dim(1), label("color"))
- axis(dim(1), label("cut"))
- axis(dim(2), label("count"))
Hadley Wickham : Layered grammar of graphics
이번에는 Hadley Wickham의 Layered grammar of graphics 를 살펴보겠습니다. 우선 Wilkinson 의 기존 문법에서 어떤 부분이 달라졌는지 가볍게 이야기 하고, 실제 구현체인 R의 ggplot2 라이브러리를 통해 어떤 방식으로 문법이 구성되어있는지 알아보겠습니다.
Wilkinson의 문법에서 달라진 점
우선 사용자가 그래프를 구성할 때 매번 모든 구성요소를 명시하지 않아도 동작할 수 있도록, 기본값이 적용되는 계층 구조가 생겼습니다. 예를 들면 아래와 같은 항목이 기본적으로 적용됩니다. 이러한 기본값 구조를 통해 사용자가 입력해야 하는 코드의 양을 줄일 수 있습니다.
- Stat을 생략하면, 선택한 Geom에서 Stat의 기본값을 제공합니다.
- Data 또는 Mapping 을 공통으로 정의해두면, 모든 레이어에 적용됩니다.
- 변수의 타입에 따라 기본적으로 적용되는 Scale 이 정의되어 있습니다.
- Coord를 명시하지 않을 경우 기본적으로 Cartesian 좌표계를 사용합니다.
그리고 R 언어의 특성과 라이브러리 생태계에 맞도록 내부 구성이 조정되었습니다.
- R에는 기본적으로 데이터프레임을 다루는 기능이 있으며, 데이터를 다루기 위한 생태계가 잘 준비되어 있습니다.
- 따라서 Variable Algebra 부분은 별도의 문법으로 표현하지 않습니다.
- 변수의 값을 변환하는 작업(Variable Transformation)은 별도의 시각화 문법으로 구성하지 않고, R 언어에서 정의할 수 있는 함수로 처리합니다.
Layered grammar of graphics 문서에서는 Wilkinson의 문법과 Hadley Wickham 문법의 차이를 다음과 같이 설명하고 있습니다.
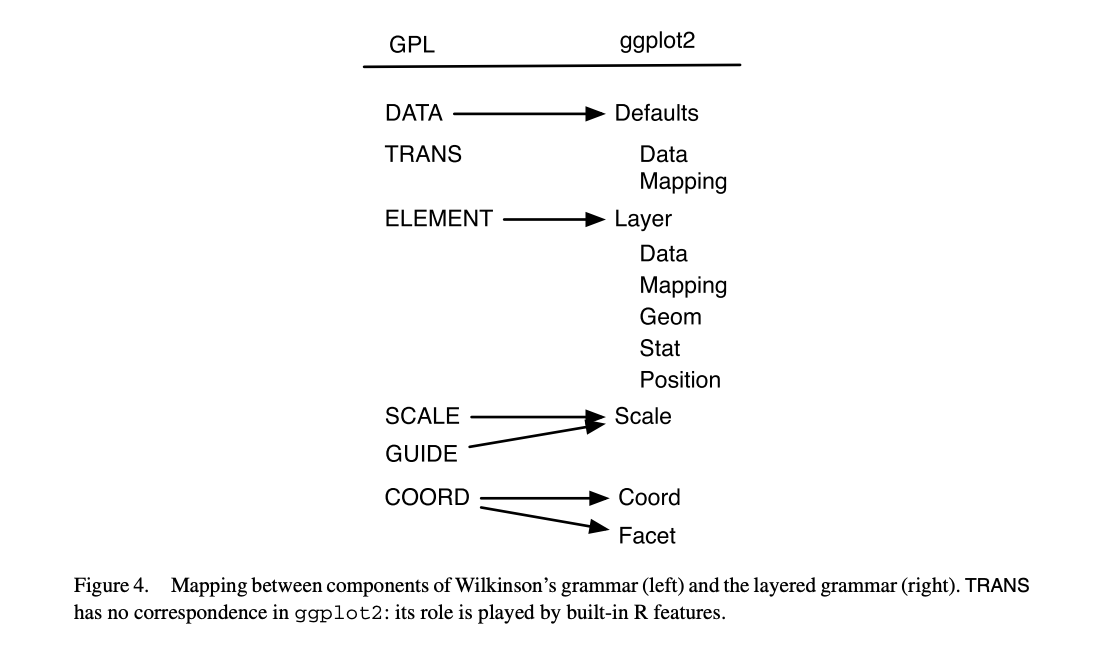
어떻게 구성되어 있을까요?
Hadley Wickham의 문법은 다음과 같이 레이어를 중심으로 구성됩니다.
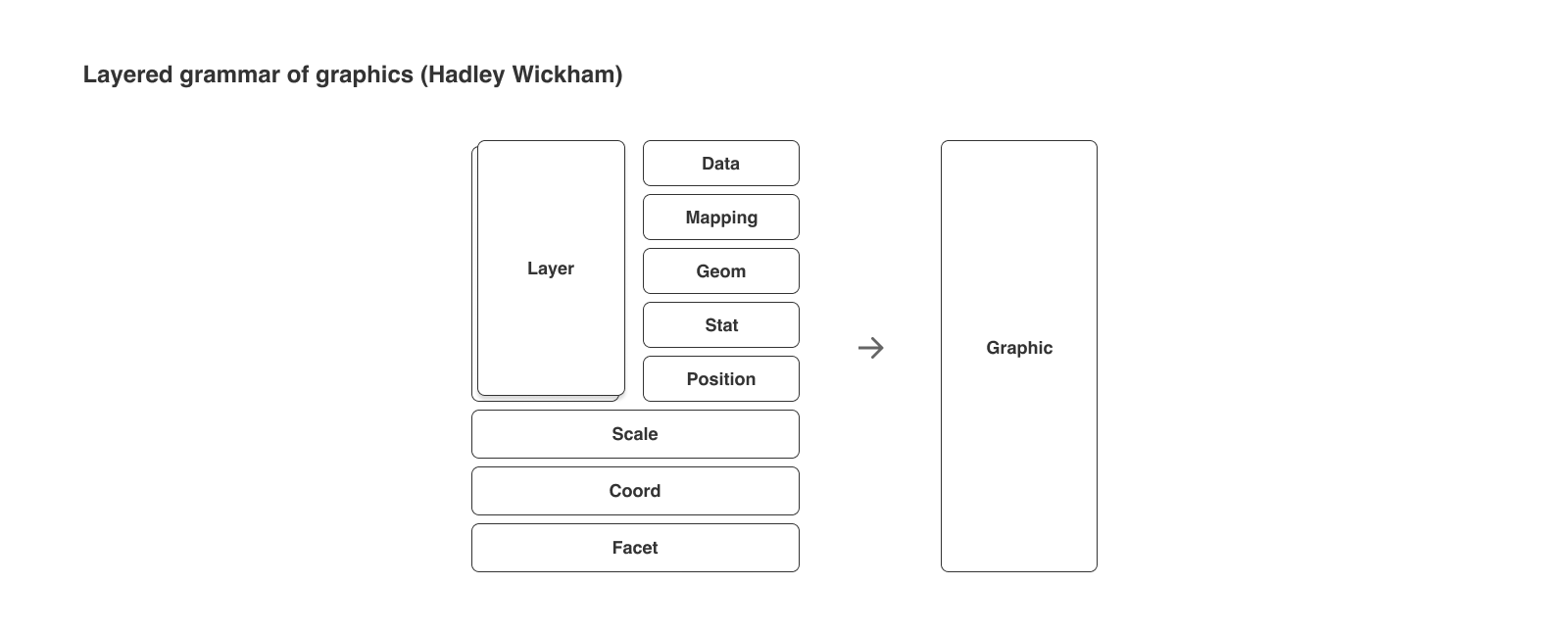
(1) Layer
그래프에서 데이터를 표현하기 위한 구성 요소를 하나의 그룹으로 관리합니다. 이 그룹을 레이어라고 합니다. 포토샵이나 다른 그래픽 도구를 사용하셨다면 레이어라는 개념도 익숙하실 텐데요. 여기서의 레이어도 여러 개의 레이어를 중첩하는 방식으로 그래프를 확장할 수 있습니다.
하나의 레이어는 다음과 같은 구성 요소로 이루어져 있습니다.
- Data & Mapping : 데이터와 함께 데이터의 각 변수를 어떤 그래픽 요소와 연결할지 명시합니다.
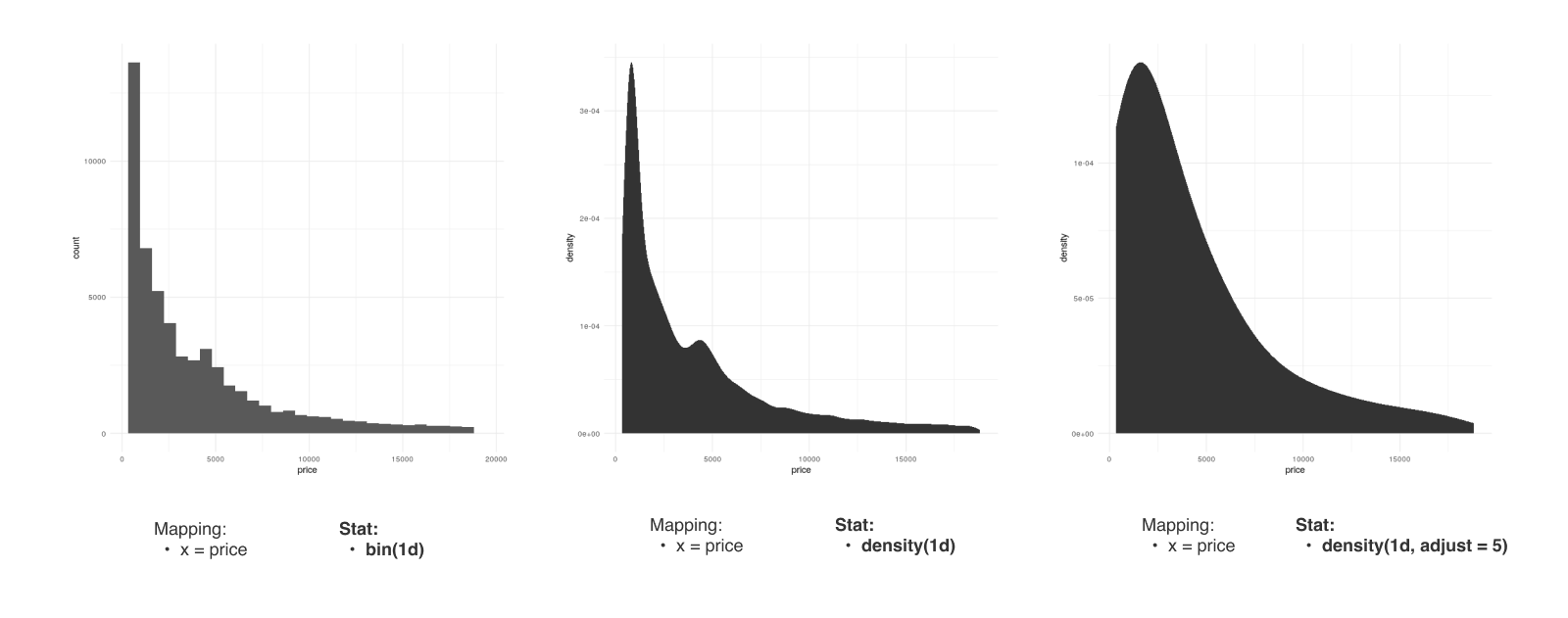
- Stat : 시각화를 위해 필요한 수치를 구하기 위해 정보를 요약하거나 변환합니다.
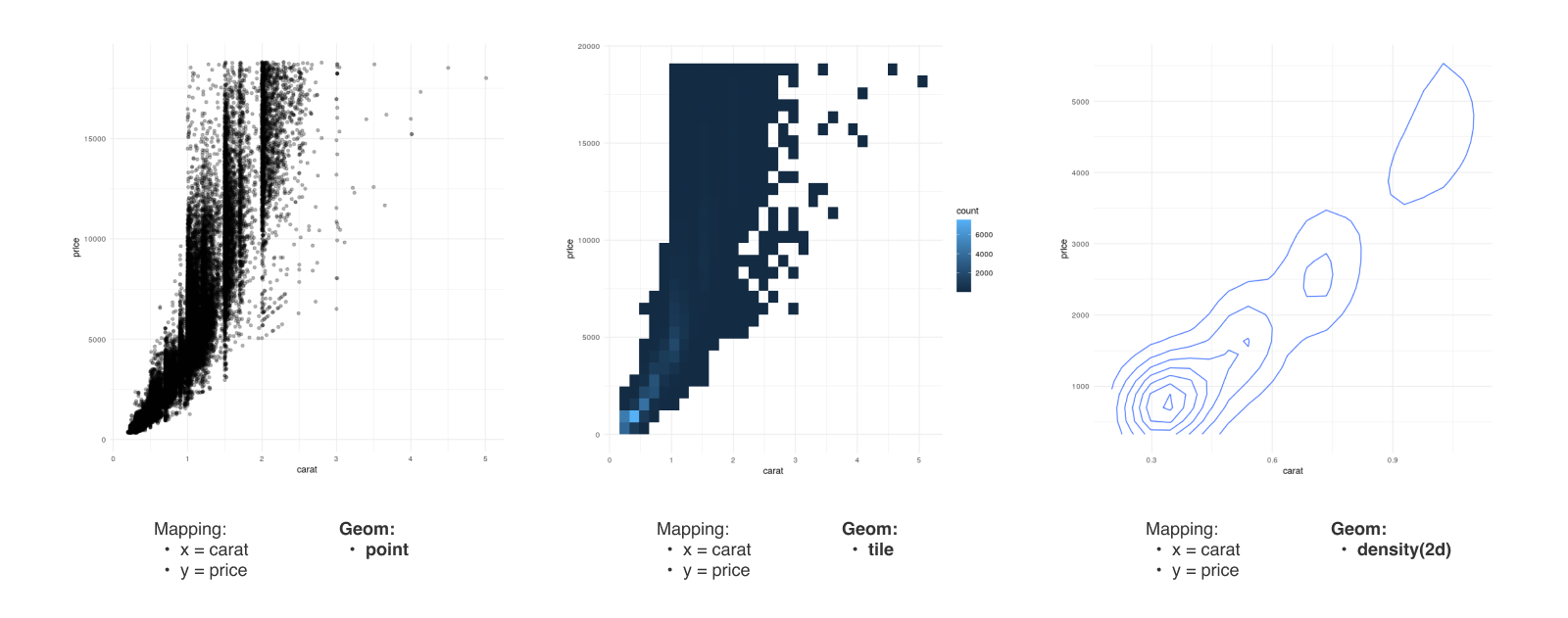
- Geom : 데이터를 어떤 형태로 표현할지 결정합니다.
- Position : 그래프 상에 여러 Geom 객체들이 겹치는 경우를 피하기 위해 위치를 조정합니다. (Wilkinson 이 Collision Modifiers 라고 표현하는 부분입니다.)
Data & Mapping
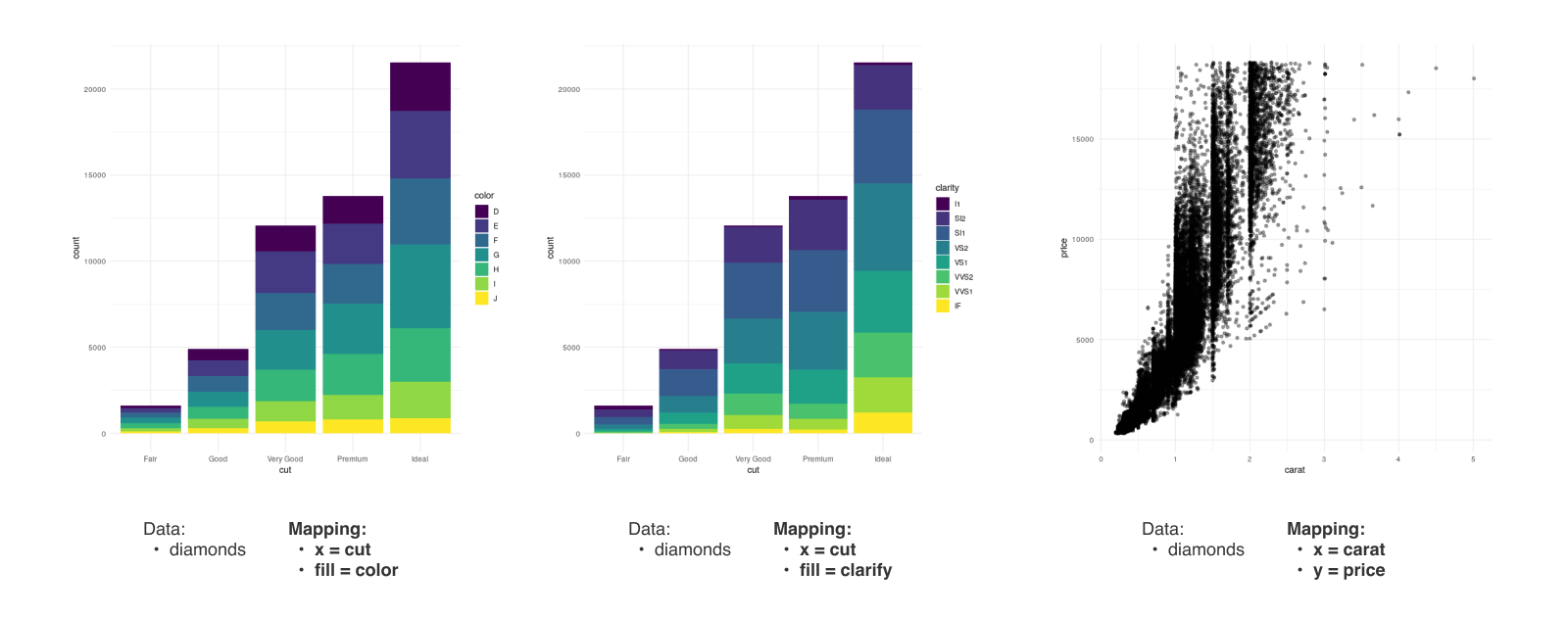
Stat
Geom
Position
(2) Scale
데이터와 시각적 요소(Aesthetic Elements)가 연결되는 과정을 세부적으로 조정합니다.
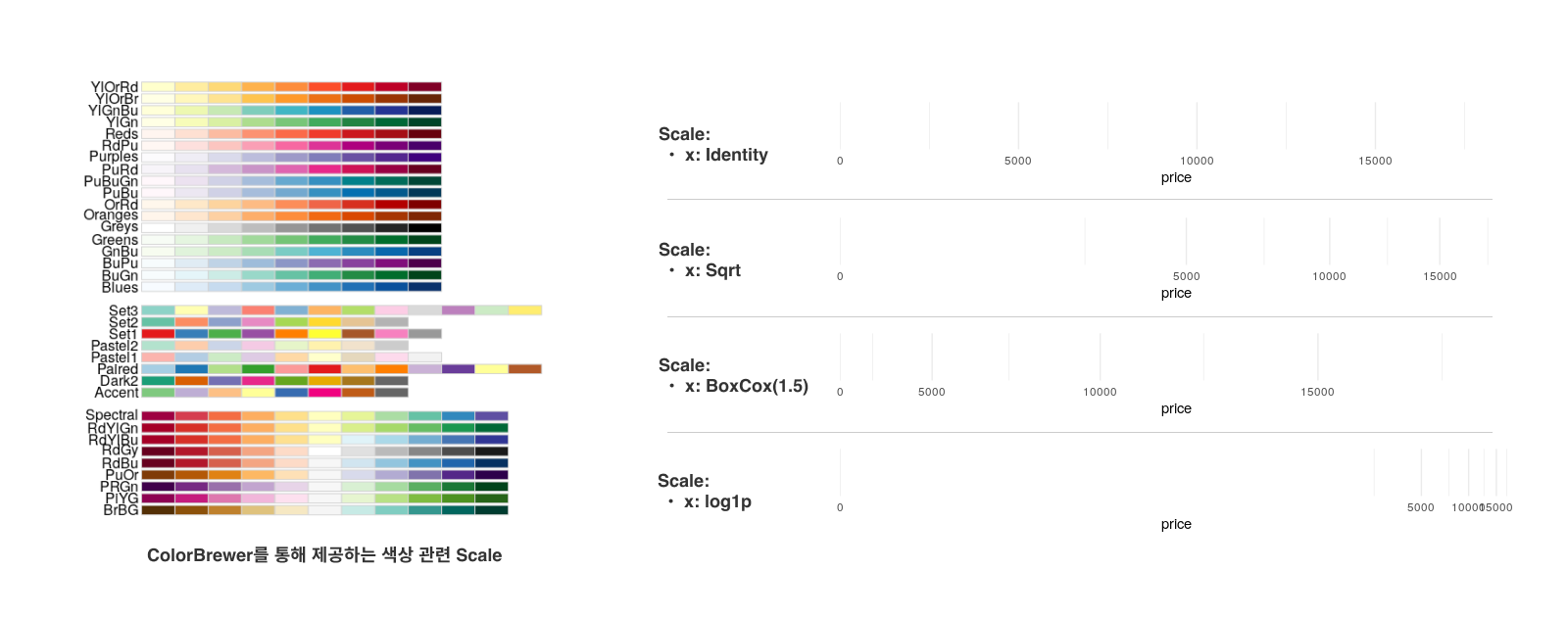
(3) Coord
오브젝트의 위치 값이 그래프에 어떻게 반영되어야 하는지 나타냅니다. 그리고 축과 그리드 선이 어떻게 그려져야 하는지 결정합니다.
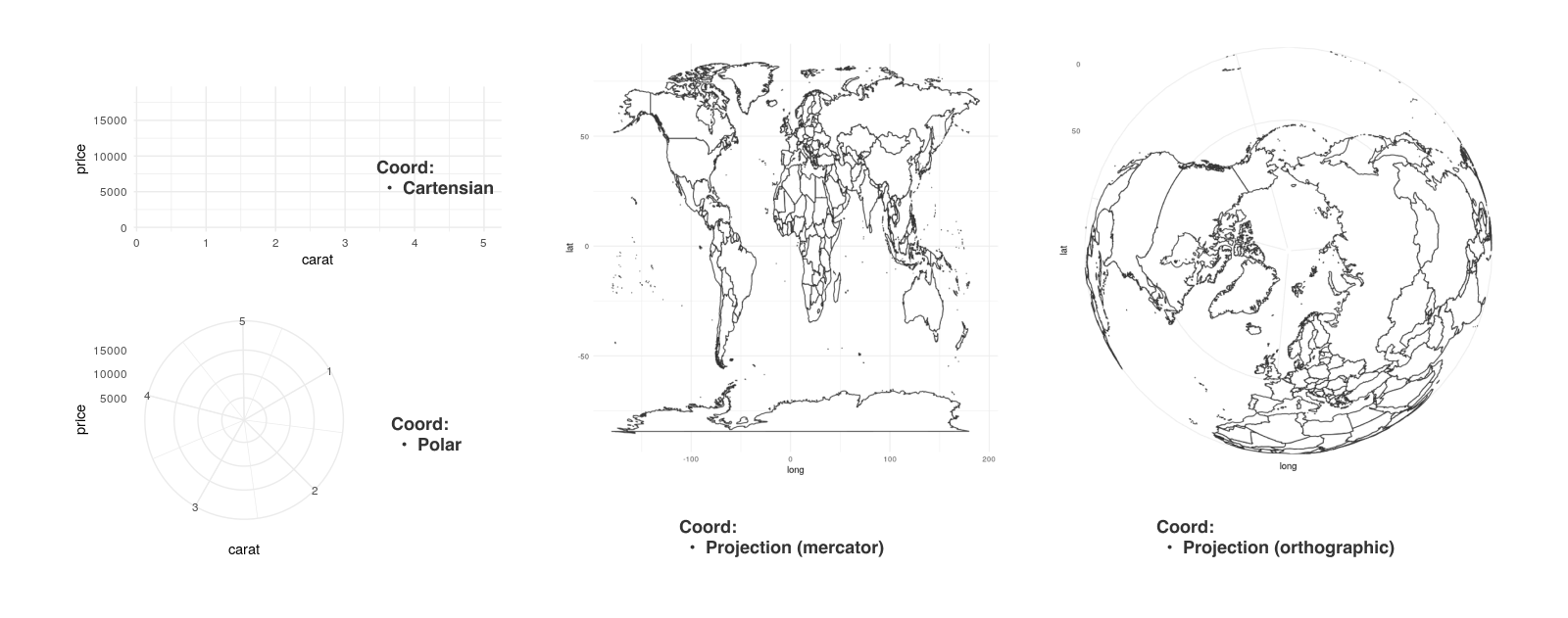
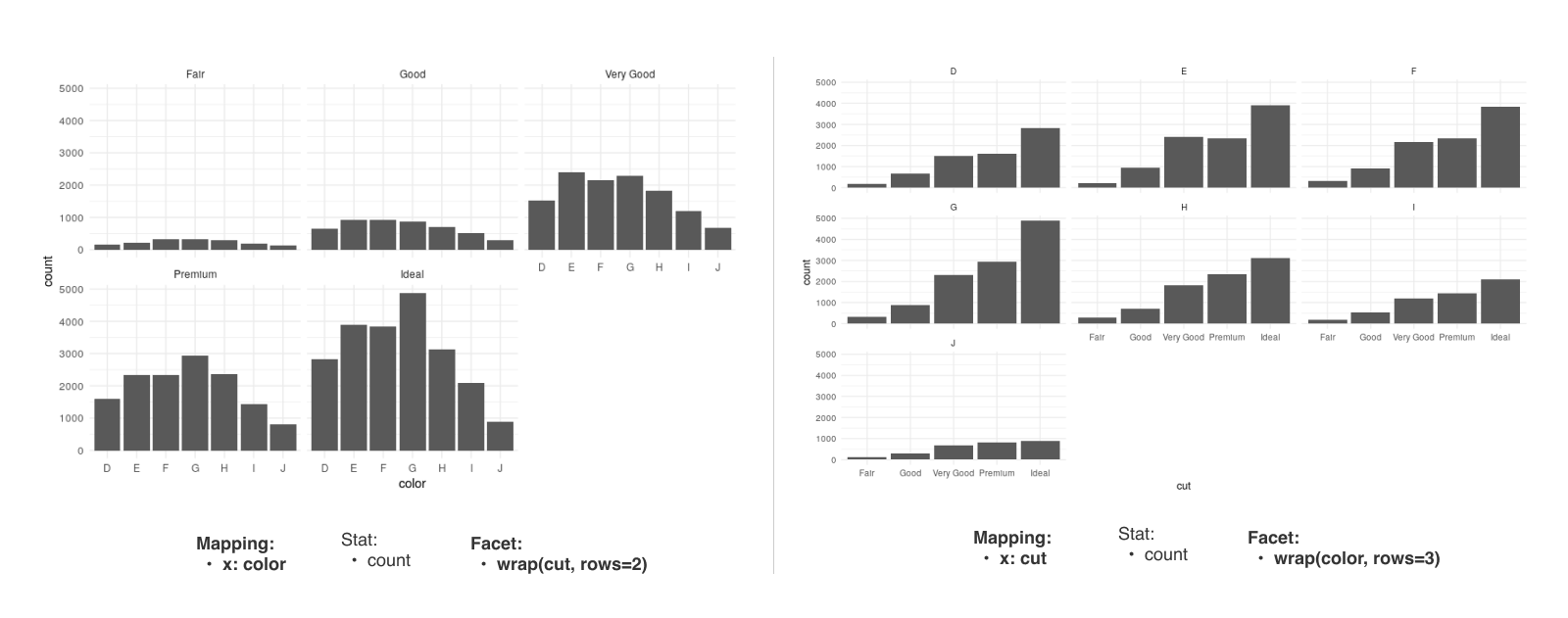
(4) Facet
전체 데이터셋을 그룹별로 나누어 보여줍니다. 어떤 변수를 기준으로 그래프가 나누어져야 하며, 어떻게 정렬해야 하는지 결정합니다.
마무리
Wilkinson의 Grammar of Graphics 는 최근 50년간 통계학의 가장 중요한 아이디어 TOP 10 에도 선정되기도 할 만큼 엄청난 영향을 미쳤습니다. 상용 시각화 서비스인 Tableau와 R의 시각화 라이브러리인 ggplot2, 그리고 Javascript의 Vega 등 많은 도구들이 앞서 설명한 문법 체계를 바탕으로 탄탄한 생태계를 쌓아 올렸습니다. 또, 데이터 과학에서 EDA 등 시각화를 기반으로 한 다양한 분석 기법들이 뿌리내리는데 큰 도움을 주었습니다.
저는 R을 공부하면서 접하게 된 ggplot2 라이브러리를 통해 처음 시각화 문법을 접하게 되었습니다. 그리고 복잡한 수학이나 개발을 어려워하던 제가 데이터에 본격적으로 재미를 붙이게 된 계기이기도 합니다. 처음에는 코드 몇 줄로 그럴싸한 그래프가 출력되는 것이 신기한 것이었지만, 얼마 지나지 않아서 잘 구성된 시각화가 가지는 힘이 엄청나게 강하다는 것을 알게 되었습니다. 제가 중요하다고 생각하는 정보를 다른 사람들도 중요하다고 느끼도록 설득하는 것이 바로 제가 하는 일이었거든요.
사실 워낙 시각화 도구들의 문서가 잘 작성되어 있어서, 이런 원론적인 내용을 모르더라도 간단한 그래프를 그리는데는 아무런 문제가 없습니다. 하지만 전달해야 하는 내용이 너무 많거나 복잡할 때는 문법 체계를 명확하게 알고 있다는 것이 큰 도움이 될 거에요. 결국 우리가 하려는 건 데이터를 기반으로 하는 의사소통이니까요.
