

CausalImpact
CausalImpact는 무엇이고, 왜 필요할까?
CausalImpact는 시계열 데이터에서 의도적인 개입으로 인한 인과 효과를 추정하기 위한 방법론입니다.
인과 효과를 확인하려면 A/B 테스트처럼 실험을 하는 것이 제일 좋습니다. 하지만 마케팅, 광고, 웹 서비스 등을 운영하다보면 실험을 수행하는 것이 어려운 경우가 많습니다. 특히 다음과 같은 상황에서는 이상적인 randomised design이 어려운 경우가 많이 발생합니다.
- 신호와 소음의 비율을 비교했을 때 신호의 비율이 낮은 편입니다.
- 여러 계절성이 나타날 수 있습니다.
- 관측되지 않은 변수들과 변수간의 상호작용으로 인해 교란효과가 발생할 수 있습니다.
“광고 캠페인을 적용했을 때 일별 클릭수는 얼마나 증가했을까?” 같은 질문은 실험이 불가능한 상황에서 답변하는 것이 매우 어렵습니다. 이러한 상황에서 우리는 CausalImpact를 통해 신제품 출시나 광고 캠페인의 시작/종료 등 특정 시점에 발생한 이벤트가 목표로 하는 지표에 미친 영향을 측정하고자 합니다.
이전에는 위와 같은 상황에서 보통 어떤 방식으로 문제를 해결했을까요? 기존에는 실험군과 대조군에 대해서 개입 전후의 인과 효과를 설명하기 위한 방법으로 Difference-in-differences (DiD) 라는 방법을 많이 사용했습니다. 시작하기 전에 DiD 방법론에 대해 가볍게 살펴보겠습니다.
Difference-in-differences
이벤트가 적용된 실험군과 이벤트가 적용되지 않은 대조군이 있습니다. DiD 모형은 실험군과 대조군의 개입(이벤트) 전후를 설명하는 선형 모형을 구성합니다. (1) 실험군과 대조군 각각의 개입 전후 차이를 비교합니다. (2) 그리고 실험군과 통제군의 차이를 비교합니다. 차이 안에서 한 번 더 차이를 비교하면 이벤트로 인한 효과를 분리할 수 있습니다.

굉장히 심플하고 직관적이기 때문에 많이 사용되지만, DiD 방법론에는 한계점이 있습니다.
- (1) DiD는 iid 가정을 바탕으로 하는 정적인 회귀 모형을 사용하는데, 데이터는 시간에 따라 변하는 특성을 가지고 있습니다.
- (2) 대부분의 DiD 분석은 개입 이전과 이후로만 나누어서 분석합니다. 시간에 따라 효과가 변하는 경우에는 인과 효과를 정확하게 추정할 수 없습니다.
CausalImpact 에서는 DiD 방법론의 한계점을 해결하기 위해, 상태-공간 모형에 유연한 회귀 모형 컴포넌트를 결합하여 관측 결과가 시간에 따라 어떻게 변했는지 설명했습니다.
CausalImpact는 어떻게 동작할까?
개입이 발생하지 않았을 경우를 예측하기 위해 사용할 수 있는 접근법으로 여러 예측 변수를 모아 하나의 가상 대조군 데이터를 추정하는 방식이 있습니다. 그러면 가상의 대조군과 실제 시계열의 차이를 인과 효과로 볼 수 있습니다.
CausalImpact 에서는 결과 변수에 해당하는 시계열과(예. 클릭수) 통제 변수에 해당하는 시계열 (예. 개입이 적용되지 않은 영역의 클릭수 또는 다른 사이트의 클릭수)가 주어졌을 때, 베이지안 구조적 시계열 모형(Bayesian Structural time-series model)을 구축합니다. 학습한 시계열 모형을 통해 만약 특정 시점에 개입이 일어나지 않았다면 그 이후에 지표가 어떻게 되었을지(counterfactual)를 예측합니다. 이 예측 결과를 가상의 대조군으로 두고 인과 효과를 추정하게 됩니다.
CausalImpact 모형은 다음과 같은 가정을 포함합니다.
- 통제 변수(Control) 역할을 하는 시계열은 개입의 영향을 받지 않아야 합니다.
- 개입 이전 시점의 공변량과 결과 변수의 관계가 개입 이후에도 유지되어야 합니다. (dynamic regression을 적용할 경우, 이 가정을 완화시킬 수 있습니다.)
- 모형에 Prior가 포함되어 있다는 사실을 명심해야 합니다.
- 예를 들어, CausalImpact가 기본적으로 시계열 학습에 사용하는 모형은 Local Level 을 위해 Gaussian random walk 를 사용하는데, 이 때 random walk의 표준 편차에 Prior가 설정되어 있습니다.
모형에 대한 디테일한 설명
베이지안 구조적 시계열 모형
CausalImpact 내부에서 가상의 대조군을 추정하기 위한 방법으로 베이지안 구조적 시계열 모형을 사용합니다. 이번에는 베이지안 구조적 시계열 모형에 대해 간단히 살펴보려고 합니다.
구조적 시계열 모형은 시계열 데이터를 위한 상태-공간 모형입니다. 현재 상태를 바탕으로 관측 결과를 설명하는 식(Observation equation)과 현재 상태를 통해 다음 상태를 설명하는 식(State equation)으로 구성되어 있습니다.
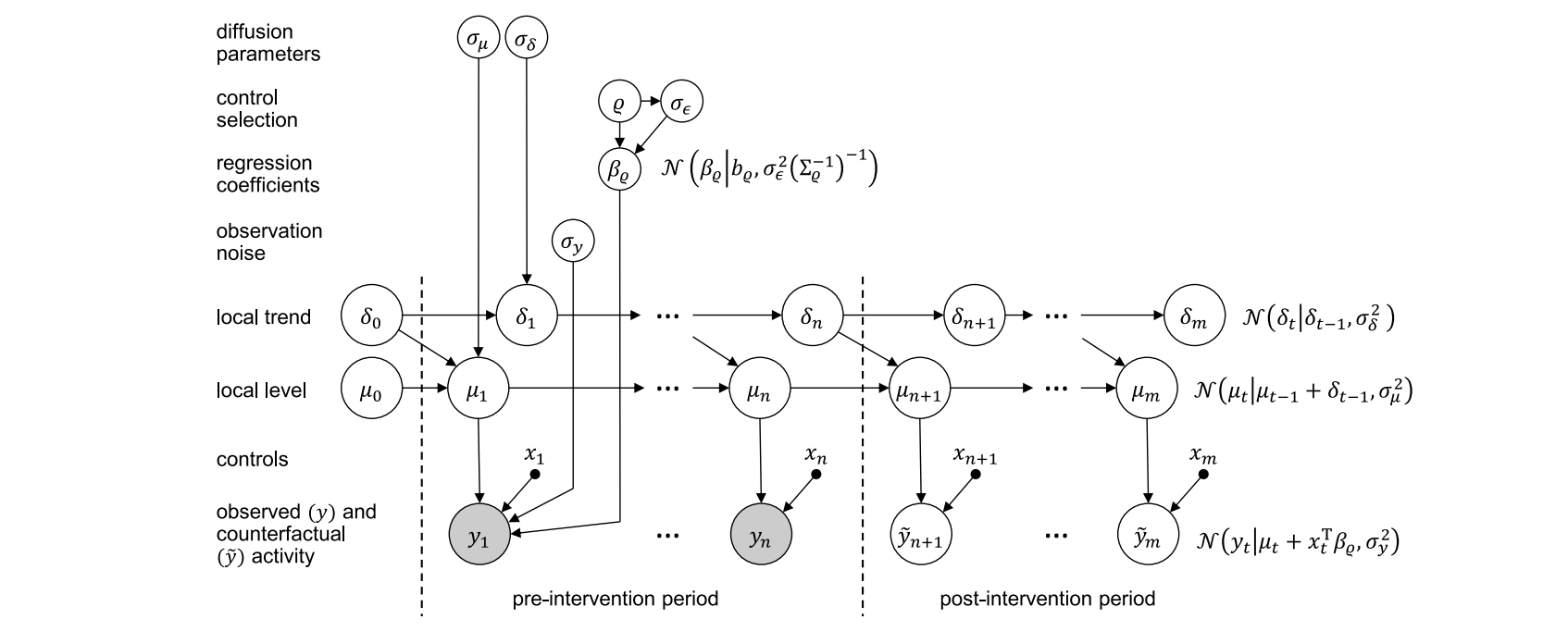
구조적 시계열 모형은 유연하고 모듈화가 가능하기 때문에 매우 실용적입니다. ARIMA 모형을 포함하여 다양한 계절성과 특정 공휴일 또는 이벤트로 인한 효과까지 모형으로 표현할 수 있습니다.
CausalImpact 내부에 사용된 모형은 크게 트렌드, 계절성, 회귀 모형이라는 3가지 상태 컴포넌트로 구성되어 있습니다.
- (1) 트렌드
- 기본적으로 사용하는
Local Linear Trend컴포넌트는 drift term을 포함하는 랜덤 워크로 구성되어 있습니다. drift term에 해당하는 부분이 트렌드의 기울기를 표현하게 됩니다. Local Linear Trend는 단기 트렌드 예측에 유리하도록 구성되어 있습니다.- 베이지안 구조적 시계열 모형을 구현한 bsts 라이브러리에서는 랜덤워크의 기울기 부분만 정상성을 만족하는 AR(1)으로 대체하여 장기 트렌드 예측에 사용할 수 있는 별도의 컴포넌트를 제공합니다.
bsts라이브러리에서는 해당 컴포넌트를Semilocal Linear Trend라고 부릅니다.
- 기본적으로 사용하는
- (2) 계절성
- S개의 시즌 효과를 모두 합쳤을 때 0 이 되도록 모형을 학습합니다.
- 예를 들어,
S=4로 설정하여 사계절의 효과를 확인할 경우, 겨울의 효과는-1 x (봄 + 여름 + 가을)이 됩니다. - 시즌의 길이는 임의로 조정할 수 있습니다. 일별 데이터에서 요일 효과를 알고자 한다면
S=7로 두면 됩니다.
- (3) 동일한 시점의 공변량과 회귀모형 계수
- 보통은 시간에 따라 변수들의 계수가 변하지 않는 static regression을 사용합니다. 하지만 시간에 따라 변수간의 관계가 변하는 경우 dynamic regression을 적용할 수 있습니다.
- spike-and-slab prior를 사용해 공변량 중에서 예측에 포함되어야 하는 의미있는 변수만 모형에 반영합니다. 이를 통해 오버피팅을 피하게 되는 효과도 있습니다.
- 모든 공변량은 예측하려는 시계열과 같은 시간대의 정보를 가집니다. 현재 모형에서는 시계열간의 시차를 고려하지 않습니다.
효과를 추정하는 과정
모형 구성이 완료되면 데이터를 통해 파라미터를 추론합니다. 파라미터 추론은 크게 다음과 같은 세 가지 단계로 이루어집니다.
- MCMC를 통해 개입 이전의 관측 데이터를 바탕으로 모형 파라미터와 상태 벡터를 시뮬레이션합니다.
- 개입 이전의 목표 시계열과 전체 기간의 공변량을 반영하여 개입이 없었을 경우의 시계열 분포를 시뮬레이션합니다.
- 2번의 posterior 샘플링 결과를 통해 시점별 인과 효과와 누적 인과 효과의 사후 분포를 구합니다.
파라미터 추론이 완료되면 추론 결과를 바탕으로 인과 효과를 계산합니다.
- 각 시점의 실제 시계열과 개입이 없을 경우를 가정해 예측한 가상의 대조군 시계열의 차이를 구하면 시점별(pointwise) 효과를 구할 수 있습니다.
- 개입 이후의 누적 효과를 계산할 수도 있는데, 단위 시간동안 계산하는 지표(검색수, 회원가입 수, 매출, 설치 또는 가입 수)의 경우 누적 효과가 해석에 도움이 될 수 있습니다.
- 반면 특정 시점에서만 의미 있는 수치들(특정 시점의 고객수, 구독자수)은 오히려 누적 효과를 통해 해석하기 어렵습니다.
데이터가 CausalImpact 모형의 가정을 만족하는지 어떻게 확인할까?
CausalImpact 라이브러리의 공식 문서에 따르면 다음과 같은 방법으로 시작해보면 좋다고 합니다.
- (1) 왜 모형에 포함된 공변량들이 개입의 영향을 받지 않았는지 고민해야 합니다.
- 모든 공변량을 그래프로 그려서 시각적으로 확인해 볼 필요도 있습니다.
- (2) 개입 이전 시점까지의 시계열을 얼마나 잘 예측하는지 확인해야 합니다. 임의의 시점에 가상의 개입이 이루어졌다고 가정하고 모형을 학습하면 어떤 결론이 나오는지 확인해봅니다. 이 때 counterfactual 예측과 실제값이 비슷해서 통계적으로 유의미하지 않은 결론이 나와야 합니다.
- (3) 모형의 학습 결과를 공유할 때는 가정한 내용들과 모형의 파라미터를 포함하여 공유합니다. 다른 사람들과 함께 유효한 가정인지, 적절한 파라미터를 사용한 것인지 논의하는 것이 좋습니다.
마무리
최근들어 인과 추론과 관련된 내용이 이전보다 많이 알려지게 되면서, 업무적으로도 활용할 기회가 많이 생겨나고 있습니다. CausalImpact 같은 모형의 경우에는 이벤트 등 개입이 적용되지 않았으면서 실제 목표 시계열을 예측하는데 도움이 되는 지표를 찾아야 하는데요. 지표를 찾는 과정에서 오히려 도메인 지식에 대한 중요성을 깨닫게 되었습니다. 데이터가 어떻게 만들어지는지, 비즈니스나 사이트의 특성에 따라 지표 추이에 어떤 영향을 미치는지 고민하는 시간이 많아졌습니다. 분석을 하는 입장에서 내가 분석하려는 대상에 대해 잘 알고 있어야 한다는, 당연하지만 잠시 잊고 있던 내용을 새삼 느끼고 있습니다.
인과 추론과 관련하여 현업에서 일하면서 경험했던 것들을 정리하여 2021년 네이버 DEVIEW 에서 발표하게 되었습니다. 활용 사례가 궁금하신 분들은 다음 링크에서 발표 내용을 확인해보세요!
